
A febre pela modernização aplicacional e micro serviços trazem muitos benefícios para a gestão do ciclo de vida das nossas aplicações, mas também nos trazem novos desafios. Quantos de nós já nos deparámos com temas como garantir escalabilidade aplicacional? Como externalizar o estado da minha aplicação? Como sei que a minha aplicação está a correr dentro do que é expectável?
Uma das maiores preocupações, e na minha opinião das mais importantes, é saber o comportamento da nossa aplicação em operação. No dia a dia, que indicadores devemos medir e como é que os medimos? Como é que atingimos observabilidade nos nossos sistemas?
Observabilidade
O que é que consideramos observabilidade no contexto de sistemas? A observabilidade de um sistema traduz-se na medição do estado interno do mesmo, através da análise dos seus “outputs”. E tal como detalhado no Chapter 4. The Three Pillars of Observability – Distributed Systems Observability, podemos dividir observabilidade em 3 pilares:
- logging – os logs gerados por um sistema permitem-nos analisar eventos aplicacionais
- tracing – a captura da execução do programa dá-nos visibilidade sobre os timings e interdependências de execução
- Métricas – extração de indicadores que nos dão uma visão sobre a performance da aplicação

Focando no pilar das métricas, uma das ferramentas open source mais adotada pela comunidade para este fim é o Prometheus. As oportunidades de já termos instâncias de Prometheus nas nossas organizações são muito elevadas, até porque a solução promove a facilidade de extração e a normalização do formato com que expomos as nossas métricas, facilitando a portabilidade e a replicabilidade da solução.
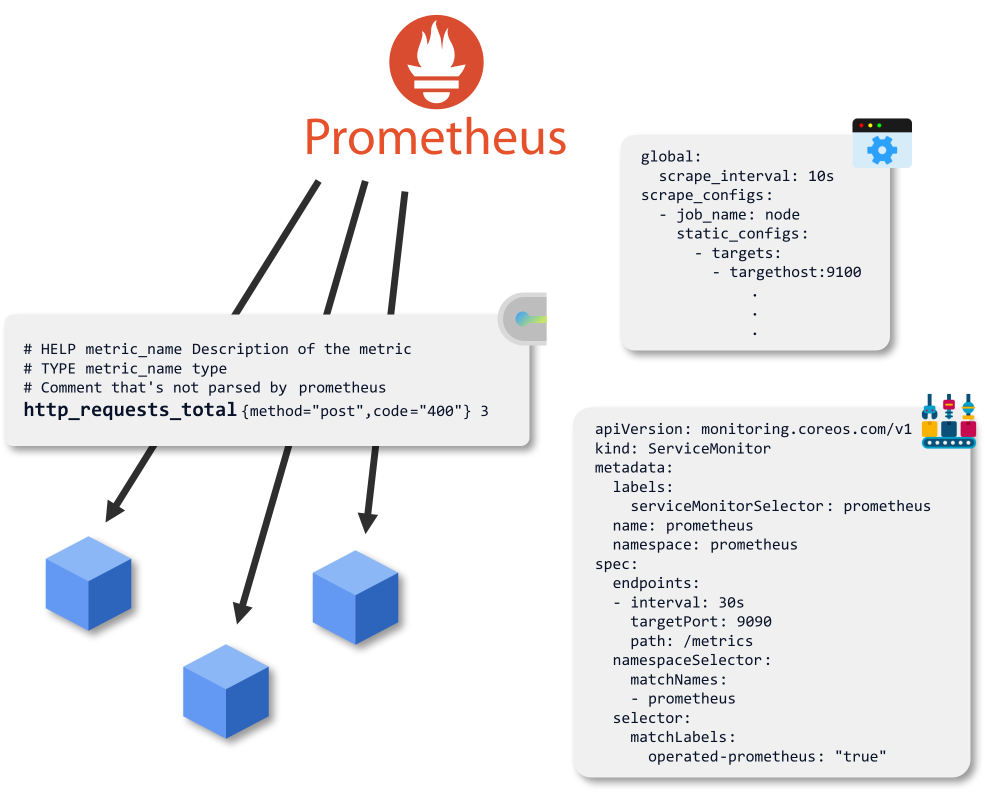
E agora pergunto, quantas equipas tem na sua organização? E quantas aplicações são desenvolvidas e geridas por essas mesmas equipas? Estas aplicações têm observabilidade implementada?
Novos desafios surgem quando olhamos para o tema em escala. A resiliência das nossas aplicações é extremamente importante, especialmente porque estas aplicações fazem parte/são o nosso negócio, e a distribuição dos sistemas por múltiplas clouds é uma realidade de hoje em dia. Contudo, gerir um sistema sem observabilidade é gerir um sistema às cegas.
Um dos desafios da recolha de métricas distribuídas é o aparecimento de várias instâncias de Prometheus isoladas, trazendo assim uma dificuldade na consolidação de métricas.
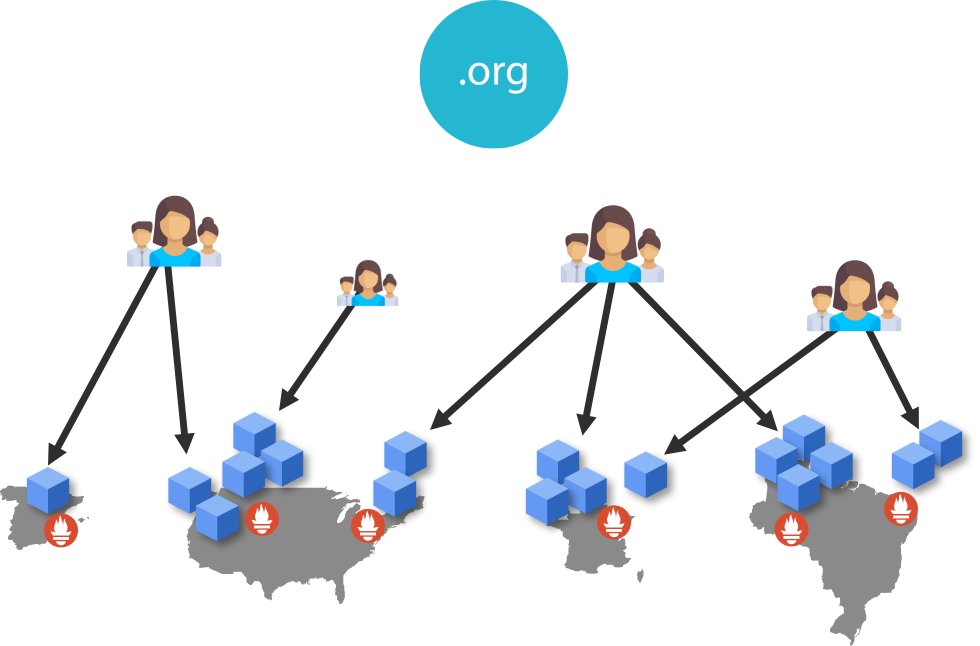
Para consolidarmos estas métricas, devemos ser capazes de centralizá-las sobre um único ponto de consumo, de preferência sem comprometer a infraestrutura das métricas existente.
Uma ferramenta que responde a todos estes temas é o Thanos.
Gestão de métricas distribuídas com Thanos
O Thanos é uma solução open source que centraliza as métricas e integra com Prometheus já existentes, pelo que não é necessário substituir a base de Prometheus que utilizamos à data de hoje.
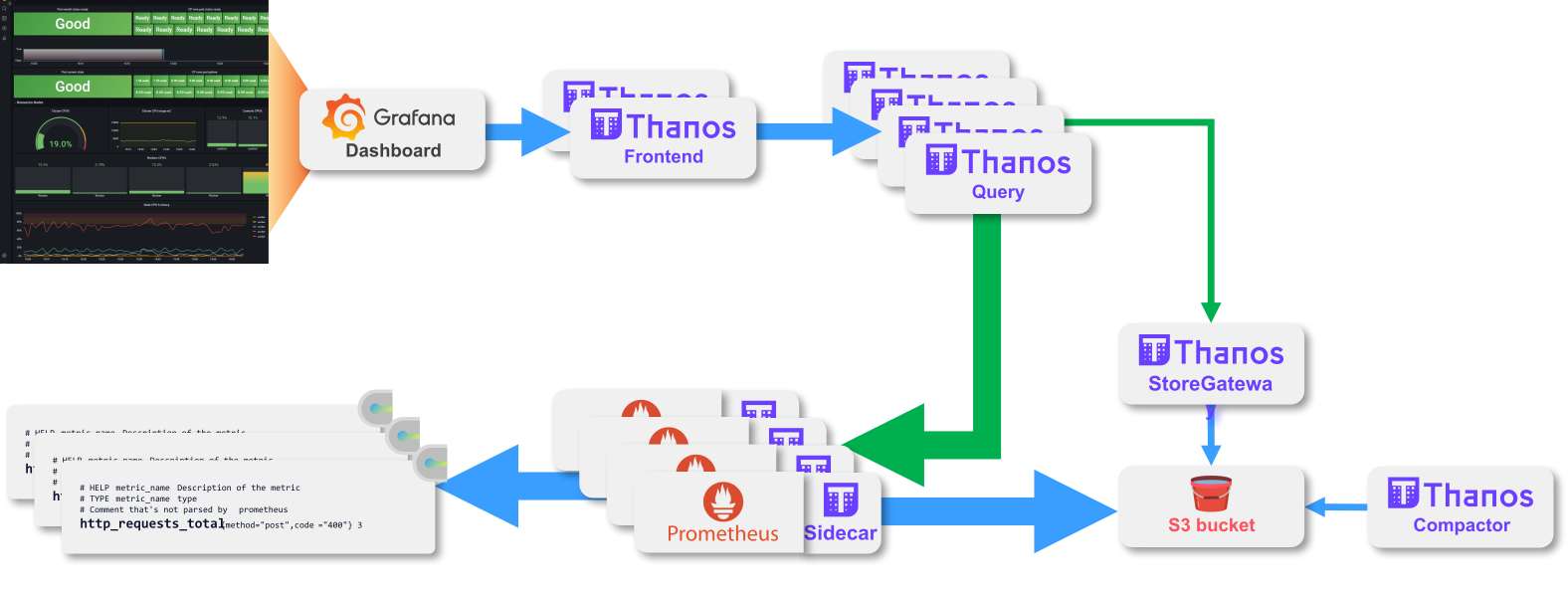
Esta arquitetura permite-nos olhar para as instâncias de Prometheus como ferramentas de extração de métricas de curta duração em edge, exportando-as posteriormente para um repositório de longa retenção, acabando por reduzir a complexidade de configuração e gestão dos Prometheus. Além disso, a escalabilidade da integração é abismal. O aparecimento de novos projetos com novas instâncias de Prometheus passam a ser um no issue, dada a simplicidade de integração.
A integração é importante, mas também são importantes otimizações no consumo das métricas. Com o Thanos, estas otimizações fazem-se sentir até mesmo na camada de gestão dos dados de longa retenção. A certo ponto, todos nós já tivemos de esperar por um relatório de dados históricos devido à extração de milhares de datapoints. Para além da gestão do tempo de retenção dos dados, o Thanos também trata da manipulação da amostragem dos mesmos, acelerando o consumo das métricas.
Outra vertente da otimização do consumo de dados vem da escalabilidade do Thanos em si. Com o Thanos, é possível partir um pedido de dados em múltiplas partes, paralelizando a recolha de dados para um consumo exponencialmente mais rápido.
Conclusão
Num ponto de vista geral, com o Thanos conseguimos centralizar o consumo das nossas métricas, garantir a sua longa retenção, facilmente integrar e escalar a solução e ainda otimizar o consumo dos nossos dados. Tudo isto reduzindo a complexidade e garantido a observabilidade dos nossos sistemas, para uma gestão de métricas distribuídas em sistemas multicloud.
Posto isto, nem tudo o que medimos nos ajuda na operação. Um mar de métricas acaba por trazer mais ruído do que objetividade para a operação. Mais um desafio, para outro dia.
Gostaria de ouvir a sua opinião sobre observabilidade e como endereça o desafio.
