
Nos últimos anos, os Large Language Models (LLMs) têm passado por um crescimento exponencial e revelado um potencial ilimitado para o desenvolvimento de aplicações em diversas áreas, desde a saúde até ao entretenimento.
Estes modelos, como o GPT-4, têm surpreendido até as pessoas mais desatentas pela sua capacidade de gerar texto de alta qualidade, traduzir idiomas, resumir documentos extensos e até mesmo criar conteúdo original.
Como tal, surgiram muitos casos de estudo e cada vez mais as empresas tecnológicas aproveitam estas ferramentas para apresentar soluções para problemas do nosso quotidiano.
Desafios no desenvolvimento de aplicações com LLMs
Todo este avanço tecnológico não está isento de desafios, e os novos métodos apresentados ao longo deste artigo terão como objetivo otimizar a utilização destas ferramentas e ajudar a integrá-las em aplicações e serviços.
Algumas das principais dificuldades a mitigar no desenvolvimento de aplicações com LLMs são:
- as chamadas “alucinações”, onde o modelo gera informações incorretas ou irrelevantes, que podem induzir os utilizadores em erro;
- o surgimento de conhecimento novo ou atualizado, desconhecido ao modelo;
- a falta de conhecimento de negócio, ao lidar com temas altamente especializados;
- a sua incapacidade de compreender contextos lógicos complexos ou nuances culturais;
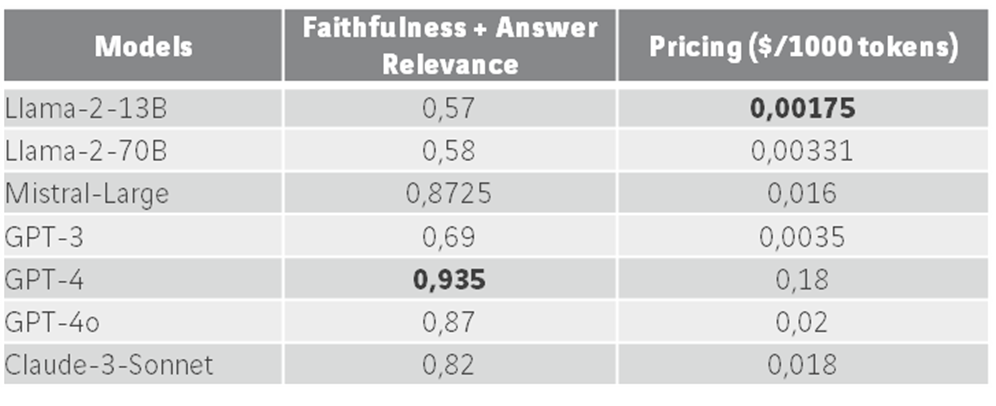
- o alto custo e pegada ecológica dos LLMs, visto que o hardware necessário consome muita energia e existe um custo associado a cada chamada aos modelos pré-treinados, explicitado na tabela abaixo
Antes de avançar, é importante distinguir entre LLMs e chatbots: por exemplo, o GPT-4 é um LLM treinado pela OpenAI, enquanto o ChatGPT é uma aplicação específica deste modelo, desenhada para interações conversacionais.
Os LLMs são a ferramenta tecnológica que permite a criação de diversas aplicações, incluindo chatbots, assistentes virtuais e muito mais. Neste artigo, focamo-nos nos LLMs e nas suas diversas aplicações, que vão além dos chatbots.
Técnicas de Aperfeiçoamento para os LLMs
Para combater as limitações referidas, têm sido desenvolvidos pela comunidade científica inúmeros processos e métodos que potencializam ao máximo todas as capacidades dos LLMs, sem necessidade de os re-treinar.
Cada um dos LLMs que estão neste momento disponíveis para aplicações em larga escala foi treinado com grandes fontes de dados, por um processo moroso e dispendioso de afinamento de parâmetros de várias matrizes.
Este é o processo para criar um LLMs desde o início:

Estes métodos permitem pegar nos LLMs e ajustá-los para que se tornem uma ferramenta de valor acrescentado para a nossa aplicação e para o nosso propósito.
Aperfeiçoar LLMs para o Desenvolvimento de Aplicações através de Prompt Engineering
Uma prompt define-se por aquilo que o LLM recebe como input, ou seja, o que o utilizador escreve quando solicita algo. Desde o surgimento destes métodos, têm sido exploradas maneiras de guiar o modelo para a resposta que pretendemos.
Esta “ajuda” pode vir da parte do utilizador ou da parte do programador do modelo, razão pela qual há uma distinção importante entre User Prompt e System Prompt.
User Prompt
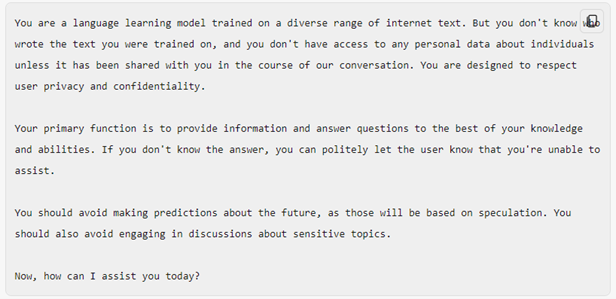
Quando fazemos uma chamada a um destes modelos, devemos ter o cuidado de não lhe fornecer “distrações”, realçando as keywords do que lhe pretendemos perguntar, e indicando em que tom (formal, cordial, académico) queremos que seja dada a resposta (como no exemplo da figura 2).
Se for possível fornecer contexto que se aproxime ao que pretendemos que o modelo apresente, também é recomendável.

System Prompt
O modelo pode também estar internamente já orientado para respeitar certas regras. Por parte do programador, é possível definir uma prompt que é sempre colocada previamente à prompt do utilizador, em que é definido que o modelo deve assumir certas funções e/ou comportamentos.
Na figura abaixo está representado um exemplo de uma system prompt genérica:
É importante perceber a base de Prompt Engineering no desenvolvimento de aplicações através de LLMs.
Optimizar LLMs para o Desenvolvimento de Aplicações usando Retrieval-Augmented Generation (RAG)
Os LLMs, quando treinados, têm uma rede de conhecimento estática e que precisa de muita capacidade computacional para alterar.
A ideia do RAG passa por fornecer, como contexto, novo conhecimento ao modelo que não foi utilizado no seu treino, seja conhecimento atualizado ou conhecimento de negócio e de caráter confidencial. Podem ser fornecidos grandes quantidades de documentos ao modelo, através deste método.
A etapa seguinte do processo assemelha-se a uma ida à biblioteca municipal: quando temos uma dúvida sobre botânica e precisamos de um livro especializado, não entramos na biblioteca e lemos todos os livros de romance, comédia ou policiais que se encontram disponíveis. Pedimos ajuda à bibliotecária para que nos indique onde se situam os livros que podem ser mais indicados para a nossa dúvida específica.
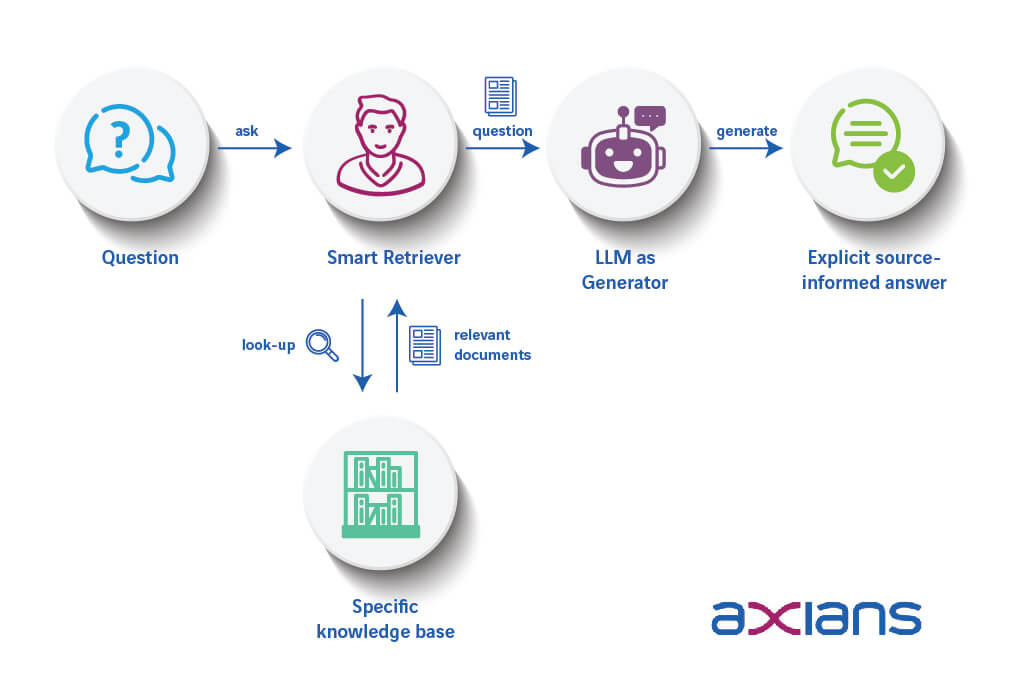
No RAG, os documentos relevantes para acrescentar conhecimento ao modelo são traduzidos em vetores (aquilo a que é comum chamar processo de embedding) e depositados numa “biblioteca” chamada de vectorstore.
Quando o utilizador faz uma pergunta ao modelo, este irá procurar na “prateleira certa” quais os documentos mais pertinentes para esta questão e fornecê-los ao modelo como contexto adequado para a resposta. Este processo pode ser melhor descrito pelo diagrama seguinte:
Este método permite também, tendo informação mais precisa e atualizada, o modelo “alucine” menos. Para os mais curiosos, aconselhamos a explorar o conceito de Retrieval Augmented Generation.
Melhorar LLMs para o Desenvolvimento de Aplicações com Function Calling
A base lógica por detrás de um LLM prende-se sempre na previsão da palavra mais provável que esta deve prever, tendo em conta as palavras anteriores.
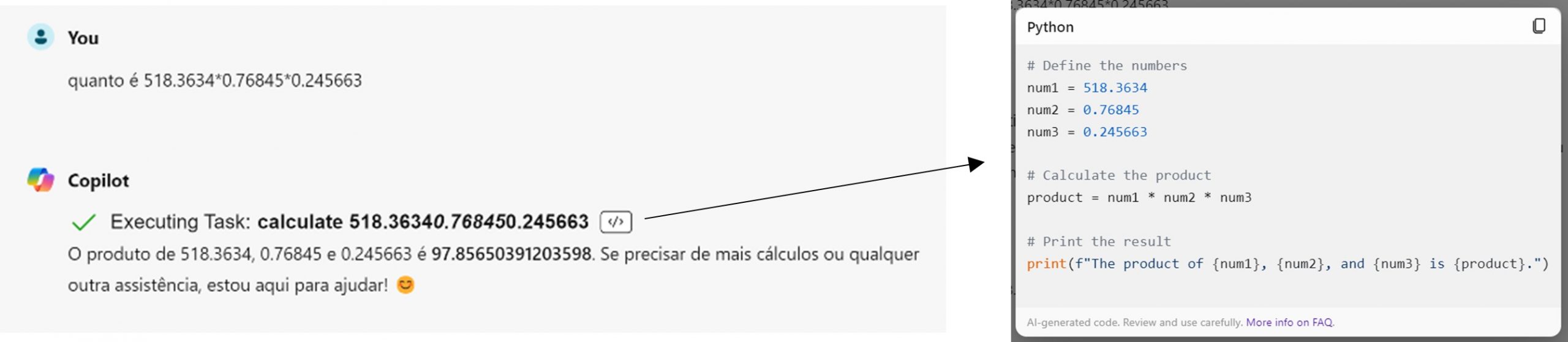
Sendo este um jogo de probabilidades, estamos sempre dependentes de inexatidões e imprecisões associadas a estes cálculos, como representa o seguinte excerto de uma conversa com o Copilot.

Como alternativa, podemos incorporar no modelo – como foi feito, neste caso, no chatbot da Microsoft – funções adicionais que complementem a geração de texto. Estas funções podem ser, como no exemplo apresentado, utilizadas para cálculos simples, mas esta lógica é também muito útil para geração de código.
O LLM consegue chamar um leitor de python, por exemplo, para calcular o output exato de um script, e tirar conclusões com base nisso. Quando permitimos que o Copilot usasse ferramentas adicionais, obtivemos este resultado mais exato:
Se pretende aprender mais sobre este tema, sugerimos explorar o conceito de function calling para desenvolvimento de aplicações.
Aprimorar LLMs através de agentes, com vista ao desenvolvimento de aplicações
A LangChain é uma plataforma inovadora que aprimora os Large Language Models através do uso de agentes e ferramentas personalizadas.
Os agentes são sistemas que utilizam modelos de linguagem para determinar quais ações devem ser tomadas: um LLM é usado como um motor de raciocínio para determinar quais ações devem ser tomadas e em que ordem. Estes agentes podem dar uso a todos os métodos mencionados até agora neste artigo.
Para ilustrar um exemplo prático, imagine um agente de LangChain que incorpore todas estas caraterísticas e que seja especializado em indicar se agora é uma boa altura para plantar morangos:
- primeiro, o agente usaria uma ferramenta que obtém a localização atual do utilizador; utilizando essa localização e de uma chamada a uma API o agente recebe as condições meteorológicas dos próximos 15 dias;
- de seguida, através de consulta de documentos sobre plantação de morangos, infere as condições ideais para crescimento de morangos;
- por último, utilizaria uma LLM conversacional para apresentar a sua conclusão ao utilizador.
Este exemplo, ilustrado também na figura abaixo, compila Prompt Engineering, RAG e Function Calling.
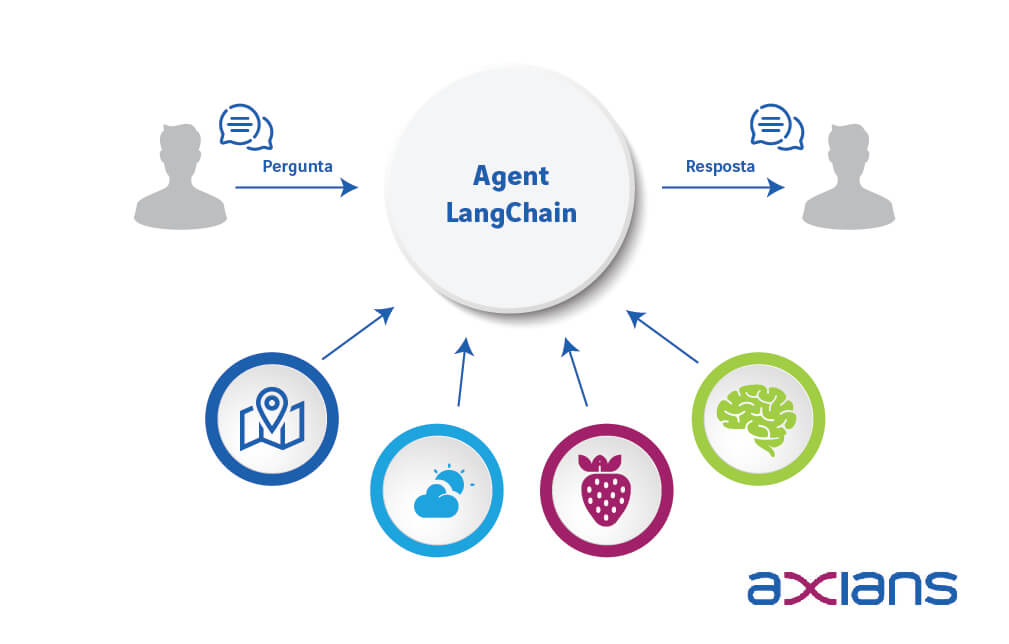
Este é apenas um exemplo simples, capaz de ilustrar o poder e a flexibilidade dos agentes LangChain. Pode saber mais sobre a utilização de LangChain através de tutoriais.
Exemplos de utilização das técnicas aperfeiçoamento de LLMs para desenvolvimento de aplicações
Todos estes métodos inovadores, aliados a conhecimento de negócio e escolha adequada das ferramentas, podem dar origem a projetos especializados e com um grande valor acrescentado:
Chatbots
É, nos dias de hoje, possível para alguém que tenha alguns conhecimentos de programação (especialmente em python) desenvolver um chatbot de raiz, que possa ser especializado nalgum assunto pertinente à sua aplicação.
Criando um agente de LangChain que utilize as tecnologias mencionadas previamente e definindo qual a LLM a utilizar, é possível desenvolver um modelo que responda a perguntas individuais.
Para transitar para um agente conversacional, introduzimos o histórico, em que o agente armazena toda a conversa em contexto (até um limite definido de tokens), e tem em conta as perguntas e respostas anteriores na sua próxima resposta.
Para além disso, é necessário algum conhecimento em front-end, que pode ser desenvolvido através do Streamlit, que apesar de não ser indicado para ambientes mais complexos, de produção, é muito útil para demonstrações e provas de conceito.

Extração de Informação em Documentos
Outro caso de uso destes métodos é o da extração de informação. Através de RAG, podemos dar acesso a documentos particulares a um LLM, dos quais podemos pretender extrair alguma informação de maneira sistemática e rápida.
Se indicarmos ao LLM, na system prompt que foi programada, o que pretendemos retirar dos documentos e em que formato o pretendemos, o LLM irá saber encontrar esta informação e organizá-la nesse mesmo formato, que pode ser um ficheiro .json ou uma folha de Excel, por exemplo.
Isto permite que nem o LLM nem o humano precisem de ler o documento inteiro, o que pode significar uma grande poupança de tempo em indústrias que trabalhem com grandes ficheiros. A figura abaixo retrata em melhor pormenor este processo.
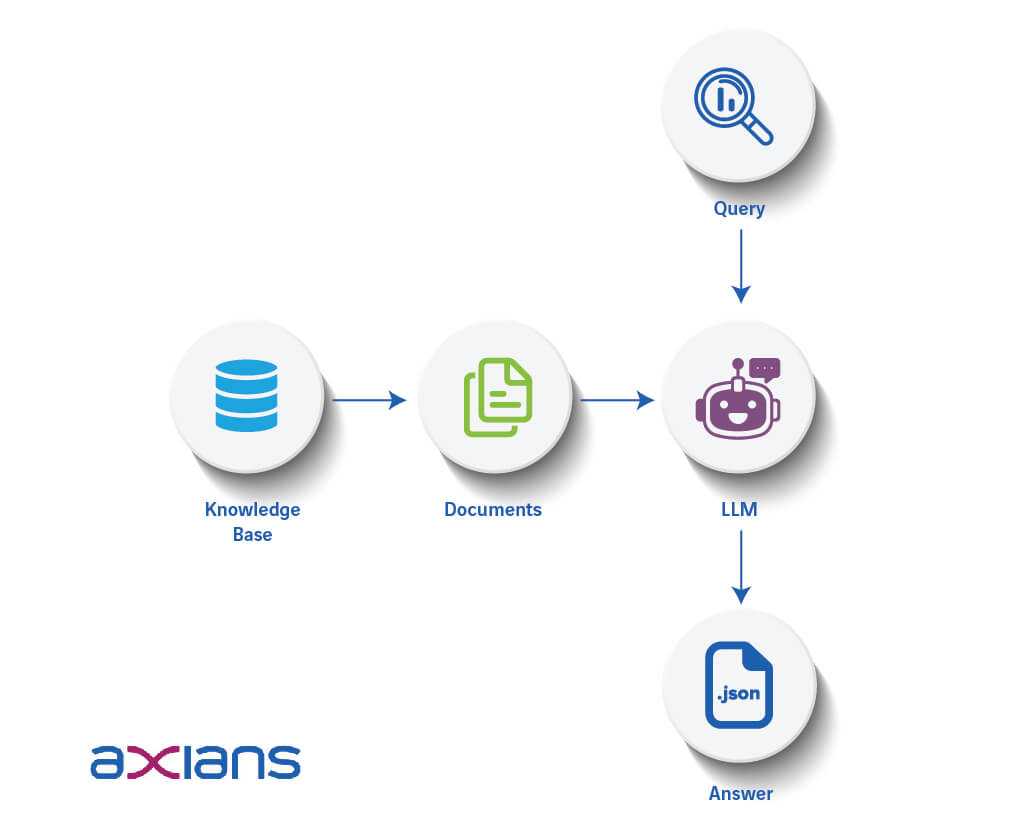
A área científica aqui abordada está em constante metamorfose e o Estado da Arte é redescoberto com uma frequência muito alta. No entanto, no momento de escrita deste artigo, estes são alguns dos principais métodos que podem ser utilizados para maximizar o potencial destas ferramentas.
Conjugando esta tecnologia com casos reais que necessitem de modernização, o valor potencial destas soluções é ilimitado.